Part 1: Introduction & Shuffle Sharding


Introduction
Overview
There are several Load-balancing algorithms out there (For eg, refer to Cloudflare docs) viz. Static(Round Robin, Weighted Round Robin etc) & Dynamic(Least Connections, Response time etc.). Each has its merits & tradeoffs. In this post, we will look at something new - the what, why & how of the Shuffle Sharding algorithm.
Why should you care?
If you ever need to distribute load among servers/workers in a multi-tenant system with the requirement that one tenant should not impact the other, then this algorithm might come in handy.
- Multi-tenancy is an architecture in which a single instance of a software application serves multiple customers (aka Tenants).
Where has it been used till now (as of 2023)?
It was introduced by AWS R53 to avoid DDoS attacks on one tenant from affecting another [3].
Used in plenty of distributed/high-scale systems like Kubernetes API server (https://kubernetes.io/docs/concepts/cluster-administration/flow-control/), Grafana Mimir & Loki etc
Overview for Part 1 of this series of posts:
Briefly cover round-robin algo (most basic algo)
Shuffle sharding
Cover basics
Cover implementation for a basic use case
Show results
Edge cases / Improvements
Part 2 will cover:
A more advanced use case (specifically Zone Aware Shuffle Sharding)
A brief comparison against other current implementations
Game on!
Problem Statement & Approach
We start with a simple known use case (i.e Round Robin alogrithm) for 2 reasons:
To get a feel for the whole flow
To validate our support ecosystem (Webserver code, Prometheus instrumentation etc.)
Goal: Implement shuffle sharding algo for a load balancer
Let's breakdown the problems into chunks:
Sub-goal 1: Implement a load balancer with simple Round-Robin algo
We need 2 code snippets:
Code for a simple Golang server with instrumentation. Reason: We want to track Request counts
Load balancer code
Sub-goal 2: Modify the LB code to use shuffle sharding
a) Read about shuffle sharding, take notes on paper etc.
b) Implement simple shuffle sharding that just prints
Sub-goal 1: Status Quo (Round-Robin)
(skip this section & move on to the next one if you just want to skim through the shuffle shard algorithm).
1.1 Setup webserver & prometheus
Set up a simple Golang HTTP server & add Prometheus instrumentation.
I have slightly modified the code from Prometheus docs to suit our use case. We want the server to respond to requests to
/pingwith apong& that server's identity.NOTE: Prometheus is not mandatory but having graphs gives a better feel for numbers & concepts. If Prometheus sounds alien/greek to you, please visit my GitHub repo where I have added shell scripts to automatically spin up servers, load balancer & Prometheus.
(Assuming 6 servers are spawned) Your prometheus.yml will look like this:
global:
scrape_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ["localhost:9090"]
- job_name: simple_server
static_configs:
- targets: ["localhost:8090", "localhost:8091", "localhost:8092", "localhost:8093", "localhost:8094", "localhost:8095"]
Run Prometheus in a docker container: docker run --rm -ti -v "$(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml" --net host prom/prometheus:v2.40.7
Ensure on the targets page (something like http://localhost:9090/targets?search=), your server state is "UP".
Now, hit the server with a curl call (like curl -H "tenant: d" http://localhost:8090/ping) and after 1-2 minutes, you should see metrics on Prometheus.
1.2 Setup a Round Robin Load Balancer
To avoid reinventing the wheel, I picked this excellent tutorial on Round-Robin based LB: https://kasvith.me/posts/lets-create-a-simple-lb-go/ (full code: https://github.com/kasvith/simplelb)
- The same code is also available in my Github repo
Now, make a bunch of HTTP requests.
You should be able to see metrics on Prometheus (query: ping_request_count).
Tinker around with this (make requests, take down a couple of servers, go thru code etc) till the flow is clear.
Sub-goal 2: Shuffle Sharding
Now that we have an idea of the whole flow, the next step would be swapping the Round-Robin algorithm with shuffle sharding.
2.1 Shuffle sharding overview
In a typical setup:
if we have a pool of 8 servers & 4 clients, requests from all clients can be sent to any of the servers. But then let's say one client starts DDoSing the pool of servers - with enough load for the server to go offline.
We still have 7 more servers as a redundancy measure. But if this sustains for a significant time, then one by one, all servers start to go down and this will affect other clients as well.
In a sharded setup:
We can assign a subset of these servers to a subset of clients (aka SHARDING), then when a client goes rogue only that subset is affected. For eg, if in a cluster of 8 servers, we have 4 shards and a client in one of the shards misbehaves, only 25% of clients are impacted.
So, from the whole service getting impacted, now only 1/X of the service is affected.
In a shuffle-sharded setup:
Imagine each client is assigned a subset of servers but for no 2 clients more than 1 overlap is present between their subset of servers.
For eg, say you have servers (s1, s2, s3) and clients (c1, c2, c3). Now c1 will be assigned (s1, s2), c2 gets (s2, s3), c3 gets (s3, s1). If c1 goes rogue then both s1 & s2 go down but the whole service is not interrupted for c2 & c3 since they have the server s3 still running for them.
The subset of servers assigned to each client is called a Shard
And since we assign (scrambled) non-overlapping servers, it's called Shuffle Sharding.
Diagram illustrates the idea further: Server instances 3 & 5 form Shard 1 and server instances 4 & 5 form Shard 2.
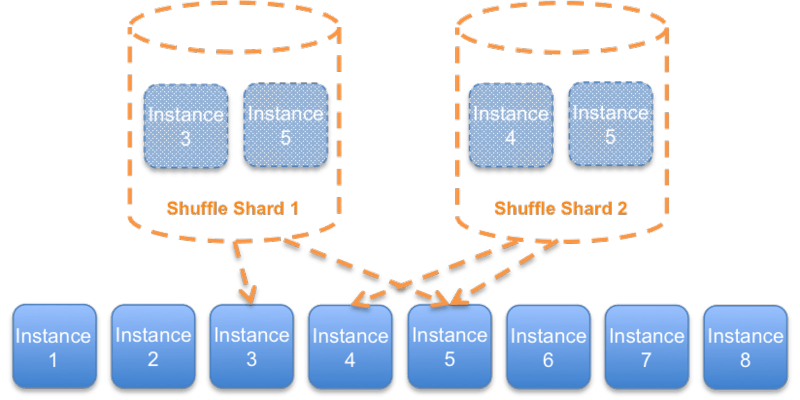
For a robust system, servers per shard will be more && likewise total server count will be high enough to avoid more than 1 overlapping server between 2 shards.
Mathematically, the number of available shards can be calculated as nCr (n choose r) where n is the total number of servers && r is servers per shard (i.e. shard size).
- For eg, in a pool of 52 servers with a shard size of 4, we can accommodate 270,725 shards i.e. 270,725 clients !!! and virtually no impact of one client on another.
2.2 Implementation
2.2.1 Strategy
Step 1: Based on the above explanation, it's easy to figure out that we just need to generate all nCr combinations given n, r and list of servers. Implementation below
// Compute all nCr combinations for 'n' servers & 'r' shardsize
func generateServerCombos(serverList []string, shardSize int) [][]string {
result := make([][]string, 0)
var util_nCr func(start int, curServerCombo []string)
util_nCr = func(start int, curServerCombo []string) {
// Basecase: When shard is full
if len(curServerCombo) == shardSize {
// make a copy of current combination
dst := make([]string, shardSize)
copy(dst, curServerCombo)
// fmt.Printf("\nAnother shard found: %v\n", dst)
result = append(result, dst)
return
}
// Traverse along array & pick `shardSize` amt of servers
for i := start; i < len(serverList); i++ {
curServerCombo = append(curServerCombo, serverList[i])
util_nCr(i+1, curServerCombo)
curServerCombo = curServerCombo[:len(curServerCombo)-1] // pop last element
}
return
}
util_nCr(1, make([]string, 0))
fmt.Println("Total number of shards: ", len(result))
// fmt.Printf("\nFinal ShardList: %v", result)
return result
}
Explanation:
Define a recursive closure (i.e. a nested function that has access to the parent function's state) that performs a DFS-like action.
We have a slice
curServerComboof lengthshardSizeinto which we add servers at each level of recursion. Within each level of recursion, we iterate through left-out elements && each one leads to a possible 'combination'.Recursion occurs till the curServerCombo is full at which point it's appended to the
resultslice.
Step 2: Once Shardpool is generated, we simply assign one client (aka tenant) to each Shardpool
- This is done by taking a hash of tenantID, modding it with no. of shards & picking the matching shard
// Function picks a randomly available shard & assigns it to client.
func fetchTenantShard(tenantID string, sp ShardPool) int {
suffix := ""
// If shard already exists
// tenantShardMapping maps tenantID to index (i.e position) of a shard
// on the array `serverShardPool` that contains all shards.
// serverShardPool looks like `[shard1, Shard2, Shard3]`
// where each Shard is of type custom struct `Shard`
if idx, ok := tenantShardMapping[tenantID]; ok {
fmt.Printf("Tenant already present: %d", idx)
return tenantShardMapping[tenantID]
}
fmt.Printf("\nTenant not found (%d). Creating one", tenantShardMapping[tenantID])
for i := 0; i < 10; i++ {
shard_idx := int(generateHash(tenantID+suffix) % uint32(len(sp)))
if !sp[shard_idx].InUseByTenant {
sp[shard_idx].InUseByTenant = true
sp[shard_idx].TenantID = tenantID
tenantShardMapping[tenantID] = shard_idx
return shard_idx
} else {
suffix = fmt.Sprint(i)
fmt.Printf("\nShard ID collision for tenant %s. So, concatenate %s suffix to generate tenant ID again", tenantID, suffix)
}
}
return -1 // too many collisions; consider different way of mapping
}
Step 3: Whenever a client makes a request, a lookup is performed to determine a shard corresponding to the tenant and then the request is forwarded to one of the servers within that shard based on an existing algo like Round Robin, Least connections etc.
And Voila! Shuffle Sharding implemented !!! (Refer GitHub[1] for boilerplates & full implementation).
2.2.2 Running the code
To start the servers
$ ./server.sh start
Inside start()
Cmd to run inside container: cd /server && chmod +x server && sleep 5 && ./server -port 8090
0ade3a3a98997b35913f386ef57d0ee5ec74655a5518711a20b4a0ffc1ec5794
...
ts=2023-06-02T21:13:15.007Z caller=main.go:512 level=info msg="No time or size retention was set so using the default time retention" duration=15d
ts=2023-06-02T21:13:15.008Z caller=main.go:556 level=info msg="Starting Prometheus Server" mode=server version="(version=2.40.7, branch=HEAD, revision=ab239ac5d43f6c1068f0d05283a0544576aaecf8)"
.
.
.
- Refer to server.sh from GitHub to see what's under the hood.
To start the load balancer
- Notice how each shard has different servers assigned to them
$ go run ss-main.go -shardsize 2 -backends "http://localhost:8090,http://localhost:8091,http://localhost:8092,http://localhost:8093,http://localhost:8094,http://localhost:8095"
Total number of shards: 15
s.initialiseShard(): [http://localhost:8090 http://localhost:8091]
s.initialiseShard(): [http://localhost:8090 http://localhost:8092]
s.initialiseShard(): [http://localhost:8090 http://localhost:8093]
s.initialiseShard(): [http://localhost:8090 http://localhost:8094]
s.initialiseShard(): [http://localhost:8090 http://localhost:8095]
s.initialiseShard(): [http://localhost:8091 http://localhost:8092]
s.initialiseShard(): [http://localhost:8091 http://localhost:8093]
s.initialiseShard(): [http://localhost:8091 http://localhost:8094]
s.initialiseShard(): [http://localhost:8091 http://localhost:8095]
s.initialiseShard(): [http://localhost:8092 http://localhost:8093]
s.initialiseShard(): [http://localhost:8092 http://localhost:8094]
s.initialiseShard(): [http://localhost:8092 http://localhost:8095]
s.initialiseShard(): [http://localhost:8093 http://localhost:8094]
s.initialiseShard(): [http://localhost:8093 http://localhost:8095]
s.initialiseShard(): [http://localhost:8094 http://localhost:8095]
.
.
.
Make Curl calls via Loadbalancer
When making a HTTP Call to the Load balancer, an HTTP Header
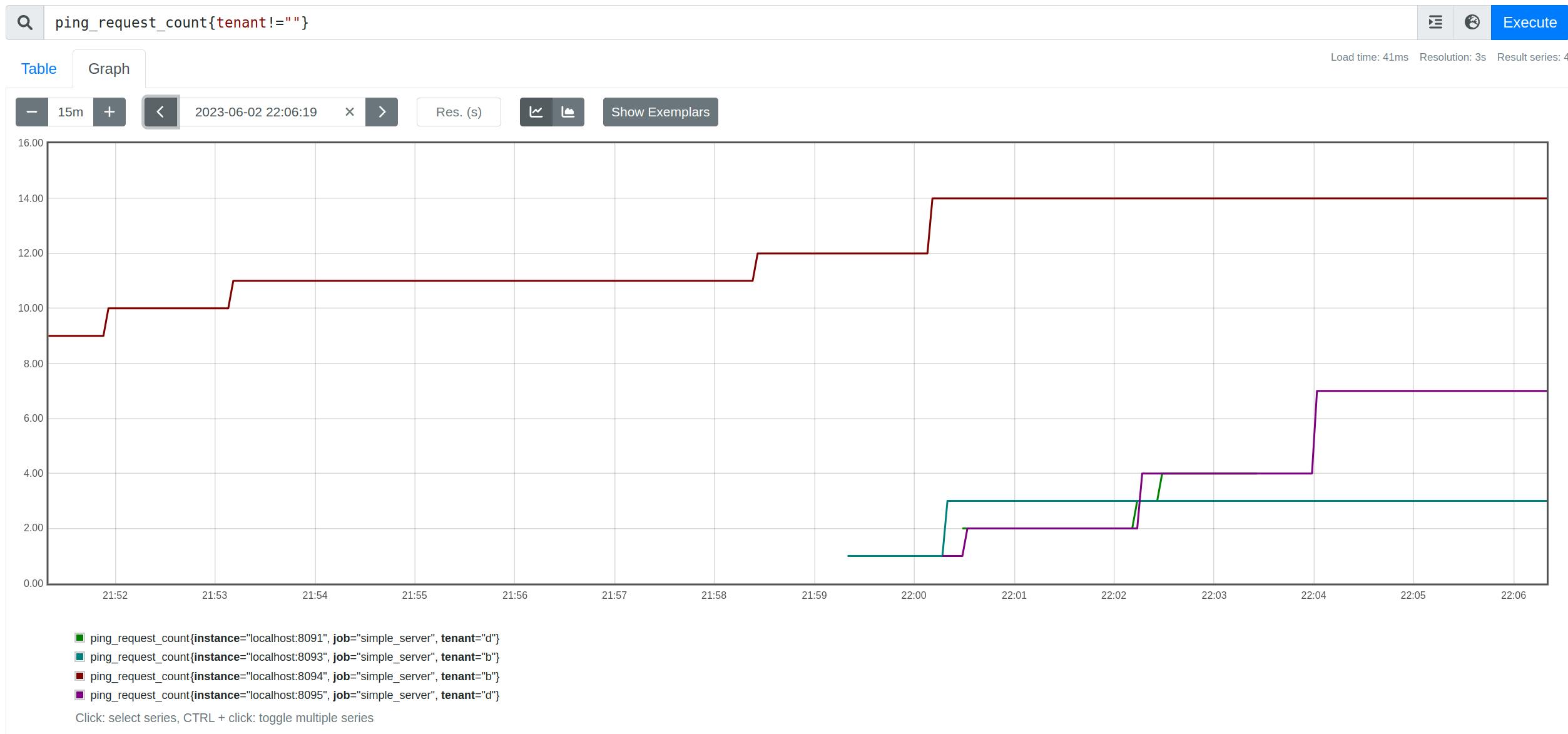
tenantis required to identify which tenant is making the request & assign the corresponding shard.We have alternating responses since within each shard, requests are routed based on round-robin.
$ curl http://localhost:3030/ping -H "tenant: b"
pong (from 8093)
$ curl http://localhost:3030/ping -H "tenant: b"
pong (from 8094)
$ curl http://localhost:3030/ping -H "tenant: b"
pong (from 8093)
...
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8095)
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8093serv)
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8095)
$ curl http://localhost:3030/ping -H "tenant: d"
Prometheus Metrics
Testing failover: Stop one of the server containers for a tenant
//Stop server-8091
$ docker stop server-8091
server-8091
/////// LB logs
2023/06/03 03:34:10
Site localhost:8091 unreachable, error: dial tcp 127.0.0.1:8091: connect: connection refused
6
2023/06/03 03:34:10 Shard status: true
///// Curl calls (notice that response comes from the same server)
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8095)
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8095)
$ curl http://localhost:3030/ping -H "tenant: d"
pong (from 8095)
2.2.3 Edgecases / Problems that haven't been considered
Addition & Removal of servers: What happens when the server(s) / boxes go down permanently? How to rebalance shards & how often do we rebalance?
- Potential solution: Should be a user-configurable interval to check shard status & when a whole shard goes down, rebalancing has to be done.
LB as a SPOF: What happens if the load balancer itself goes down?
- Potential solution: Refactor the code to make the load balancer stateless and have multiple instances of load balancers
Load imbalance: What happens when a subset of servers within each shard gets overwhelmed?
- Potential solution: Shuffle sharding is not a silver bullet. It's meant to limit blast radius in multi-tenant systems. So, to keep things stable within each shard, we'd further have to modify the round-robin algorithm to something more robust like Least Connections / Latency based distribution etc.
Session stickiness not considered: Each HTTP is considered to be independent of the previous request.
- This of course needs to be addressed inside each Shard i.e. modifying round robin to allow stickiness or modifying the backend to allow resume sessions based on client cookies etc.
HA & Multi-dimensional redundancy: Dimensions can mean, for eg, different Availability Zone (AZ), different priorities of servers etc.
- This will be addressed in Part 2 of this series
Load Testing & Performance Comparison: How does latency compare against different implementations? Can we glean other performance insights from metrics?
- This post was intended to explore the idea of shuffle sharding. In a future post, a more detailed comparison of various metrics will be explored.
Other features that a typical load balancer has: Request Queueing, IP Blocking, Client Priority / Weights, TLS Offloading etc.
Credits / Bibliography / References
[1] My Github Repo containing full implementation: https://github.com/IamGroot19/algo_implementations/tree/shuffle/load_balancing
[2] Load balancing code inspired from here: https://github.com/kasvith/simplelb)
[3] AWS Whitepaper / Blogs: